联系我们
- 东莞市屹鑫传动机械有限公司
- 联系人:曾经理
- 业务支持:130-6618-3316
- 电话:0769-22705844
- Q Q:2850619186
- 网址:www.0769yxcd.com
- 邮箱:2850619186@qq.com
- 公司地址:东莞市望牛墩镇中路天诚时代2栋101号

AlphaGo的冷思考:如何看待人工智能的进步?
本文由东莞屹鑫减速机转载:谷歌DeepMind一个15-20人组成的团队设计的系统AlphaGo在正式围棋比赛中以5:0的成绩击败了曾三次获得欧洲围棋冠军的樊麾。在非正式比赛中樊麾曾以更少的每步用时在5场比赛中获胜2场(新闻报道中常常忽略了这些更多的有趣细节,相关情况也可查看《自然》论文)。AlphaGo程序比以往任何围棋程序更加强大(下面会介绍它到底有多强)。
怎么办到的?
相比于其它计算机围棋程序相关团队,AlphaGo由一个相对较大的团队研发发,显然使用了更多的计算资源(详见下文)。该程序使用了一种新颖的方式实现了神经网络和蒙特卡洛树搜索(Monte Carlo tree search,MCTS)的结合,并经过了包含监督学习和自我训练的多个阶段的训练。值得注意的是,从评估它与人工智能进步关系的角度来看,它并没有接受过端到端(end-to-end)的训练(尽管在AAAI 2016上Demis Hassabis表示他们可能会在未来这样做)。另外在MCTS组件中它还使用了一些手工开发的功能(这一点也常常被观察者忽略)。相关论文宣称的贡献是「评估与策略网络(value and policy networks)」的构想和他们整合MCTS的方式。论文中的数据表明,使用这些元素的系统比不使用它们的系统更为强大。

整体AI性能VS特定算法的进步
仔细研究《自然》 上关于AlphaGo的论文,可以得到许多观点,其中一个对评估该结果所拥有的更广泛意义尤其重要:硬件在提高AlphaGo性能上的关键作用。参考下面的数据,我将对其进行解释。
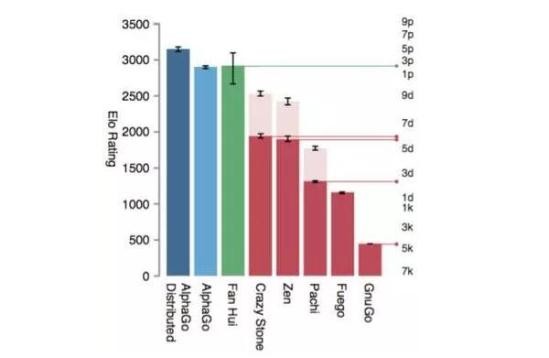
该图表显示了计算机Go与樊麾在估测Elo评级和排名方面的些许不同(译者注:Elo评级系统是由美国物理学教授Arpad Elo提出的一种计算二人竞技游戏(如象棋、围棋)中选手相对水平的评级系统)。Elo评级表示了击败评级更高或更低对手的期望概率——比如,一个评分比对手多200分的选手预计获胜的概率为四分之三。现在我们可以通过图表了解一些有趣的信息。忽略粉红色数据条(表示在有额外棋子时的表现),我们可以发现AlphaGo(不管是不是分布式的)都比原来最好的围棋程序Crazy Stone和Zen强出许多。AlphaGo的等级是较低的专业级水平(图表右侧的p表示「专业段位」),而其它程序则处在较高的业余水平上(图表右侧的d表示「业余段位」)。另外,我们可以看到尽管分布式AlphaGo(AlphaGo Distributed)的评估水平略高于樊麾,但非分布式AlphaGo却并非如此(和樊麾比赛的是分布式AlphaGo)。看起来樊麾如果和非分布式AlphaGo对弈,可能他就算不获胜,至少也可以赢几局。
后面我会谈更多关于这两种AlphaGo和其它变体之间的不同,但现在请注意一下上图遗漏的东西:最新的围棋程序。在AlphaGo的胜利之前的几周和几个月里,围棋界将显著的活动和热情(尽管团队小一些,比如Facebook就1-2个人)投入到了两个围棋引擎上:由Facebook研究人员开发的darkforest(及其变体,其中最好的是darkfmcts3)和评价很高的Zen程序的新实验版本Zen19X。
请注意,在今年一月份,Zen19X在KGS服务器(用于人类和计算机围棋)中被简单地评级为「业余7段」,据报道这是因为结合使用了神经网络。darkfmcts3则获得了实打实的「业余5段」评级,这在前几个月的基础上实现了2-3个段位的进步,其背后的研究人员还在论文中表示还有各种现成的方法可以对其进行改进。事实上,按田渊栋和朱岩在其最新的论文中的说法,在最新的KGS计算机围棋赛中,如果不是因为出现了一个故障,他们本能够击败Zen(相反Hassabis说darkfmcts3输给了Zen——他可能没有看相关的注脚!)。总结来说,计算机围棋在AlphaGo之前就已经通过与深度学习的结合实现了很多进步,这能稍微减少上面图表中的差距(这份图表可能是几个月前的),但并不能完全消除。
现在,回到硬件的问题上。DeepMind的David Silver和 Aja Huang等人对AlphaGo的许多变体版本进行了评估,并总结成了上面图表中的AlphaGo和分布式AlphaGo。但这没有给出由硬件差异所带来的变体版本的全貌,而你可以在下图(同样来自于那篇论文)中看到这个全貌。
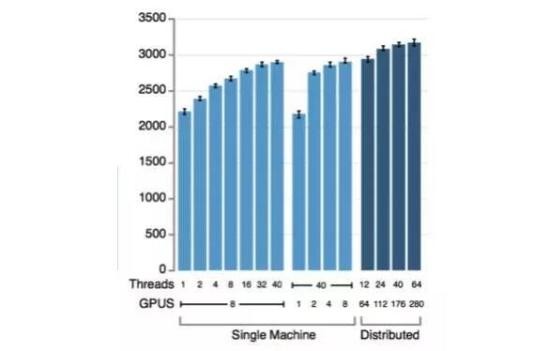
这张图表给出了不同AlphaGo变体版本所估测的Elo评级。其中11条淡蓝色数据来自「单台机器」变体,而蓝黑色数据则来自涉及多台机器的分布式AlphaGo。但这个机器到底是什么呢?图中的线程(Threads)表示了所使用的搜索线程数,而通过查阅论文后面的内容,我们可以发现其中计算最不密集的AlphaGo版本(图中最短数据条)使用了48个CPU和1个GPU。作为参考,Crazy Stone没有使用任何GPU,使用的CPU也稍微少一点。在简单搜索了不同的围棋程序目前所使用的计算集群之后,我没找到其它任何程序GPU的使用数量超过36个。Facebook的darkfmcts3是我所知唯一确定使用了GPU的版本,其最大的版本使用了64个GPU和8个CPU(也就是说相比于单台机器版AlphaGo,GPU更多,CPU更少)。上图中基于40个搜索线程、48个CPU、8个GPU变体的单台机器版AlphaGo比前面提到的其它程序强大很多。但如果它是一个48个CPU、1个GPU版本,它可能只会比Crazy Stone和Zen强一点——甚至可能不会比1月份刚改进过的最新Zen19X版本更强。
也许最好的比较是在同样硬件水平上对比AlphaGo和darkfmcts3,但它们使用了不同的CPU/GPU配置,而darkfmcts3在AlphaGo的胜利之后也已下线。如果将Crazy Stone和Zen19X扩展到与分布式AlphaGo同等的集群规模,进一步分析前面提到的硬件调整所带来的性能提升,那也会很有意思。总之,并不清楚在同等硬件水平上AlphaGo相对于之前的围棋程序有多少性能提升——也许有一些,但肯定没有之前使用小集群的围棋程序和使用大规模集群的AlphaGo之间的差距那样大。这是我们下面要讨论的。
分布式AlphaGo最大的变体版本使用了280个GPU和1920个CPU。这样巨大的硬件绝对数量所带来的算力显然远远超过之前任何被报道过的围棋程序。这一计算集群大小值得注意的原因有两个。第一,它让人疑问AlphaGo所代表的硬件适应算法(hardware-adjusted algorithmic)的进展程度,以及相关的评估和策略网络的重要性。正如我在最新的AAAI工作室论文《人工智能建模的进展》提到的,如果我们应该追踪人工智能领域内多个最先进的状况而不是单个最先进的状况,那么将分布式AlphaGo和Crazy Stone之类进行比较就是将两个最先进的进行比较——即在考虑小规模算力(和小团队)的性能和大规模算力(由十几位世界上最优秀的人工智能研究者所带来的)性能进行比较。
第二,值得注意的是,光是硬件改进这一方面就让AlphaGo实现了非常大的棋力水平跨越(相对于人类而言)——从报道中最低的大约Elo评级2200分上涨到超过3000分,这是业余水平和专业水平之间的差距。这可能表明(后面我还会回过来讨论)在可能的技术水平区间中,人类水平只能处在相对较小的区间内。如果这个项目在10或20年前已经开始,看起来很可能在相同算法的基础上,仅靠硬件提升就能让机器的棋力水平一步实现从业余水平到超人水平(超过专业水平)的跨越。此外,10或20年前,即使采用相同的算法,因为硬件水平限制,也很可能没办法开发出超人水平的围棋程序。尽管近年来神经网络和MCTS等其它方面的进步也做出了很大贡献,但也许只有到现在,在硬件进步的基础上,AlphaGo项目才有意义。
此外,同样在《人工智能建模的进展》中也简单讨论过,我们还应该考虑人工智能的性能和评估进展速率时用于训练的数据之间的关系。AlphaGo使用来自KGS服务器的大型游戏数据集帮助实现了AlphaGo的能力——我还没仔细看过过去其它相比的人工智能训练所用的数据,但看起来可能也是这个数据集。在AAAI上Hassabis表示DeepMind打算尝试完全使用自我对弈来训练AlphaGo。这是个更加了不起的想法,但在那之前,我们可能没法知道AlphaGo有多少性能来自于此数据库,这个数据库是DeepMind自己从KGS的服务器上收集的。
最后,除了调整硬件和数据,我们还应该调整如何评估一个人工智能里程牌有多重要。以深蓝(DeepBlue)为例,打败Gary Kasparov的人工智能的开发中使用了明显的相关领域专业知识,它并不是通过从头开始学习而实现该领域内的通用智能。Hassabis在AAAI和其它地方说过AlphaGo比深蓝更代表了通用型人工智能进步,而且这一技术也是为通用的目的使用的。然而,这个项目中评估和策略网络的进展与使用的具体训练方案(监督学习和自我训练的序列,而不是端到端学习)本身是由研究人员在领域内特有的专业知识所确定的,其中包括David Silver和Aja Huang,他们拥有大量关于计算机围棋和围棋方面的专业知识。尽管AlphaGo的棋力最终超过这些研究者,但其中的算法搜索都是之前由这些特定领域确定的(而且之前也提到过,部分算法——即MCTS组件——编码了特定领域的知识)。
另外,该团队非常大,有15-20人,超过我所知的之前的任何围棋引擎团队,简直能与深蓝或沃森(Watson)这样的大型项目相提并论,这在计算机围棋史上也是绝无仅有的。所以,如果我们要合理预期一个由特定领域内最聪明的顶级专家组成的团队在推动某个问题的发展,那么这个努力的规模表明我们应该稍微降低一点AlphaGo在我们印象中的里程碑意义。相反,如果例如DeepMind这样的项目只是简单地将现有的DQN算法应用到围棋上就取得了同样的成就,那就会具有更重大的意义。与此同时,由特定领域启发的创新也可能具有广泛的相关性,评估和策略网络可能就是这样的案例。现在说还有些言之过早。
总之,虽然可能最后证明评估和策略网络确实是实现更通用和更强大人工智能系统的重大进展,但我们不能在不考虑硬件调整、数据和人员的基础上就仅从AlphaGo的优秀表现上推导出这一结论。另外,不管我们认为算法创新是否尤其重要,我们都应该将这些结果理解为深度强化学习扩展应用到更大硬件组合和更多数据上的标志,也是之前大量人工智能专家眼中解决困难问题的标志,这些标志本身就是我们将要了解的有关世界的重要事实。
专家评论以及人工智能与围棋预测
AlphaGo 击败樊麾后,评论普遍认为这一突然的胜利与围棋计算机预设程序相关。需特别指出的是,DeepMind内部人士表示原以为这要十年甚至更长时间才能实现。其中就包括CrazyStone设计者Remi Coulum,他在《连线》杂志一篇文章发表了类似观点。我无意深入探讨专家对围棋计算机未来的观点,专家们几乎不可能对这一里程碑意义达成共识。
就在AlphaGo 此次胜利宣布之前,我和其他一些人在推特和其他地方表示Coulum的悲观看法并不成立。大概一年前,Alex Champandard在一次AI游戏专家的聚会上说在谷歌和其他公司的共同努力下,围棋计算机程序将实现飞跃;在去年的AAAI大会上,我也咨询了Michael Bowling(他对AI游戏也略知一二,研究了一款基本上解决了德州扑克双人限制的AI程序)having developed the AI that essentially solved limit heads-up Texas Hold Em),问他认为多少年后,围棋AI将超越人类,他回答说最多五年。所以,再次表明:这次胜利是否突然,在业内并未达成共识,那些声称该胜利意义深远的观点是基于不科学的专家调查,存在争议。
尽管如此,这一胜利也确实让包括AI专家在内的一些人感到意外,Remi Coulum这类人也不可能不知道围棋 AI。 那么,该胜利出乎专家意料之外是否意味着AI本身实现了突破呢?答案是否定的,一直以来,专家对AI未来的看法都是不可靠的。为此,我在《人工智能建模的进展》中调研了相关文献,简而言之,我们早就知道基于模型的预测优于直觉判断,定量技术预测胜于定性技术预测,qualitative ones,还有其他的因素使得我们并不该把某种所谓的直觉判断(与正规模型及其推测相反)当真。等一系列其他事情,相对于zh正式的模型/推论,我们不该对围棋 AI的未来采取特定的直观判断。而且从少数确切的经验判断可以看出,该胜利的意义并非如此重大。从为数不多的真正实证性推测(计算围棋达到人类水平的日期)来看,其预测并没有很大的误差。
Hiroshi Yamashita2011年起对围棋计算机的发展趋势进行预测,称四年后将出现围棋计算机超越人类的节点,现在看来,仅有一年的偏差。近年来,这一趋势放缓(基于KGS最高排名),如果Yamashita和其他人重新预测,也许会调整计算方式,如推迟一年。但也就在AlphaGo取得胜利的前几个星期,围棋计算机取得了突破性进展。我没有从各方面仔细看这些预测内容,但是我认为他们原本以为这个节点将在十年以后甚至更长时间才会出现,尤其是考虑到去年围棋计算机的发展。也许AlphaGo的胜利比预计早了几年,但我们也总是可以期待一些超越了(基于小团队,有限计算资源的)一般趋势的进步,因为有显著的更多投入、数据量和大量计算资源被用来攻克这一问题。
AlphaGo的发展是否偏离合理调整趋势并不明显,特别是因为如今人们并没有在严格模拟这种趋势方面投入太多工作。在不同领域中,鉴于工作、数据、硬件水平的不同,在有效的预测方法被采用之前,所谓的「突破性」进步会看上去比实际上更让人惊讶。
以上都表明我们至少应该对AlphaGo 的胜利略微淡定。虽谈不上震惊,但我也认为这是个了不起的成就。更多地,这是我们在人工智能领域取得的成就的另一标志,也展现了人工智能中使用各种方法的能力。
神经网络在AlphaGo 中起到了关键作用。将神经网络运用在围棋计算机上并不稀奇,因为神经网络用途广泛——原则上,神经网络可实现任何可计算函数。但是在AlphaGo 的运用再次表明神经网络不仅能够学习一系列的事情,还能相对高效,即在和人类处理速度相似的时间范围内、现有的硬件条件下完成一些原本需要大量人类智慧的任务。而且,它们不仅能完成诸如「模式识别」这类普通(有时人类不屑)的任务,还能规划高级策略,如在围棋中胜出所需的谋略。神经网络的可扩展性(不仅在于更大的数据量和计算性能,还在于不同的认知领域)不仅仅通过AlphaGo来展现出来,最近其它各类AI成果也有所体现。诚然,即使没有蒙特卡洛树搜索(MCTS),AlphaGo 也优于现存所有配备蒙特卡洛树搜索的系统,这也是整件事最有趣的发现之一,而一些关于AlphaGo的胜利分析却遗漏了它。AlphaGo 并不是唯一一个可展现神经网络在「认知」领域潜力的系统——近期一篇论文表明神经网络也被用于其它计划任务。
AlphaGo 能否自我训练,其表现有多少可归结于特定的训练法?现在讨论还为时过早。但是论文中对硬件规格的研究使我们有理由相信只要有足够的硬件和数据,人工智能就能极大地超越人类。这点,我们早已从ImageNet (译者注:ImageNet 是一个计算机视觉系统识别项目, 是目前世界上图像识别最大的数据库)的视觉识别结果中得知,人工智能在某些评分、语音识别和其它一些结果已经超越了人类表现。但是AlphaGo 是一个重要的象征,表明「人类水平」并非AI的终点,现有的AI技术仍有很大的提升空间,尤其是DeepMind和其他公司不断扩大的技术研究团队已经深深打上了「深度强化学习(deep reinforcement learning)」的烙印。
同时,我也深入了解了Atari 人工智能的发展细节(也许就是今后博文的主题),我也得出了相似的结论:Atari AI与人类智力大体相当只会维持非常短的一段时间,即2014-2015年。目前,游戏中表现的中间值远在人类能力的100%以上,而平均值则达到600%左右。人工智能仅在一小部分游戏中未能达到人类水平,但是很快就会出现超人类的表现。
除了从AlphaGo的胜利得到经验以外,还产生了一些其他的问题:例如:有哪些认知领域是无法通过海量计算机资源、数据和专家努力取得实质性成就的呢?经济中,关于什么是简单/困难的自动化的理论有很多,但是这些理论很少能越过人工智能所取得的成就这个表面问题,来探讨我们如何以原则性的方式定义一般而言的简单/困难认知这一更复杂的问题。另外,还有一个经验主义问题,在哪些领域已存在(超越)人类级别性能的足够数据/计算资源,或者说即将超越。比如,如果谷歌宣布开发出了语言能力高度发达的计算机个人助手,其中部分训练来自于谷歌海量数据和最新的深度(强化)学习技术,我们会感到惊讶吗?这个问题很难回答。在我看来,此类问题,包括AI安全性,对AI在认知/经济相关领域的发展提出了更严格的建模要求。
李世石之战和其它未来发展
本着基于模型的外推法胜于直觉判断的精神,我制作了以上图表,展现DeepMind尺度转换研究中CPU和Elo得分的直观联系。我将每步时长延长为相当于5分钟时间的计算,更接近于与李世石比赛的实际情况,而不是尺度转换研究中的每步2秒。这就假定在技巧水平更高的情况下,硬件运算次数不变(可能与真实情况不符,但是正如技术预测文章中写道的:初级模型也比没有模型好)。该预测指出只需提升硬件或延长AlphaGo的思考时间,AlphaGo有可能达到李世石的水平(如上图所示,3500分左右)。然而,DeepMind 几乎不可能寄希望于此——除了让AlphaGo用比研究中更长的时间进行计算最佳落子外,DeepMind还会进行大量的算法提升。Hassabis 在美国人工智能协会(AAAI)中表示他们正以各种当方式改进AlphaGo 。确实如此,他们还聘用了樊麾来帮助他们进行改进。
基于Hassabis自信表现(他可以接触相关数据,如目前的AlphaGo 比去年10月的AlphaGo 提升了多少)等诸多考虑因素,都表明AlphaGo 有很大几率击败李世石。若真成功了,我们应该进一步提升对深度强化学习可扩展性的信心,可能还包括评估/策略网络(value/policy networks)。若失败,则表明我们所认为的深度加强学习和硬件规模还没有达到我们所认为的程度,尚无法触及认知的某些方面。同样,如果自我学习被证明足以使人工智能性能相当,抑或评估/策略网络能够在其他比赛中超越人类,我们同样也应该增加现代人工智能技术扩展性和通用性的评价。
最后关于「通用AI(general AI)」(译者注:通用AI指具有对普遍问题的认知、解决能力的AI)。正如之前所提到的,Hassabis 更强调所谓的评估或策略网络的通用性,而不是深蓝(Deep Blue)的局限设计。然而事实更复杂,不能简单地一分为二(要记得,AlphaGo 为蒙特卡洛树搜索使用了某些手工开发的功能),仍然是以上所说的深度加强学习的通用性。
自DeepMind 2013年发表关于Atari的重要论文以来,深度强化学习已经被广泛应用于现实世界机器人和人机对话中以完成各类任务。考虑到在算法略微甚至无手工调试的情况下,深度强化学习已经在很多领域有了成功应用,有理由认为这些技术已经十分通用。然而,我们这里所讨论的所有案例,目前所取得的进步大部分局限于展示建立狭窄系统所需的通用方法,而不是建立通用系统所需的通用方法。前者的取得的进展并不是后者取得实质性进展的必要条件。而后者要求将机器学习迁移到至其它重要领域,也许尤其是经济或安全相关的领域,而不是局限在Atari或AlphaGo这块。
这表明严格的AI建模发展中一个重要的因素可能是确定人工智能操作系统中不同等级的通用性(而不是产生它们的通用方法,尽管这点也很重要)。这也是我感兴趣的地方,未来可能会在该领域入更多,我很好奇人们对于上述问题会怎么想。
